Content moderation is, inherently, a subjective practice.
Despite some people’s desire to have content moderation be more scientific and objective, that’s impossible.
By definition, content moderation is always going to rely on judgment calls,
and many of the judgment calls will end up in gray areas where lots of people’s opinions may differ greatly.
Indeed, one of the problems of content moderation that we’ve highlighted over the years is that to make good decisions you often need a tremendous amount of #context,
and there’s simply no way to adequately provide that at scale in a manner that actually works.
That is, when doing content moderation at scale, you need to set rules,
but rules leave little to no room for understanding context and applying it appropriately.
And thus, you get lots of crazy edge cases that end up looking bad.
We’ve seen this directly.
Last year, when we turned an entire conference of “content moderation” specialists into content moderators for an hour,
we found that there were exactly zero cases where we could get all attendees to agree on what should be done in any of the eight cases we presented.
Further, people truly underestimate the impact that “#scale” has on this equation.
Getting 99.9% of content moderation decisions at an “acceptable” level probably works fine for situations when you’re dealing with 1,000 moderation decisions per day,
but large platforms are dealing with way more than that.
If you assume that there are 1 million decisions made every day,
even with 99.9% “accuracy”
(and, remember, there’s no such thing, given the points above),
you’re still going to “miss” 1,000 calls.
But 1 million is nothing.
On Facebook alone a recent report noted that there are 350 million photos uploaded every single day.
And that’s just photos.
If there’s a 99.9% accuracy rate,
it’s still going to make “mistakes” on 350,000 images.
Every. Single. Day.
So, add another 350,000 mistakes the next day. And the next. And the next. And so on.
And, even if you could achieve such high “accuracy” and with so many mistakes,
it wouldn’t be difficult for, say, a journalist to go searching and find a bunch of those mistakes
— and point them out.
This will often come attached to a line like
“well, if a reporter can find those bad calls, why can’t Facebook?”
which leaves out that Facebook DID find that other 99.9%.
Obviously, these numbers are just illustrative, but the point stands that when you’re doing content moderation at scale,
the scale part means that even if you’re very, very, very, very good, you will still make a ridiculous number of mistakes in absolute numbers every single day.
So while I’m all for exploring different approaches to content moderation,
and see no issue with people calling out failures when they (frequently) occur,
it’s important to recognize that there is no perfect solution to content moderation,
and any company, no matter how thoughtful and deliberate and careful is going to make mistakes.
Because that’s #Masnick’s #Impossibility #Theorem
— and unless you can disprove it, we’re going to assume it’s true
https://www.techdirt.com/2019/11/20/masnicks-impossibility-theorem-content-moderation-scale-is-impossible-to-do-well/



 https://www.youtube.com/watch?v=y_GM12xjBWY 2023 Oct 25
https://www.youtube.com/watch?v=y_GM12xjBWY 2023 Oct 25









.\"")

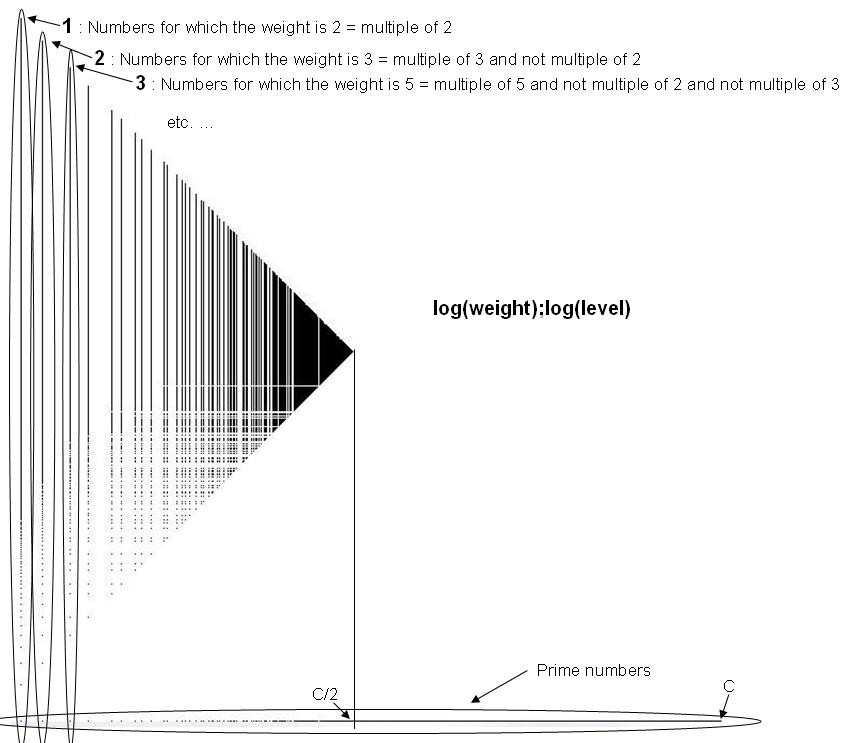
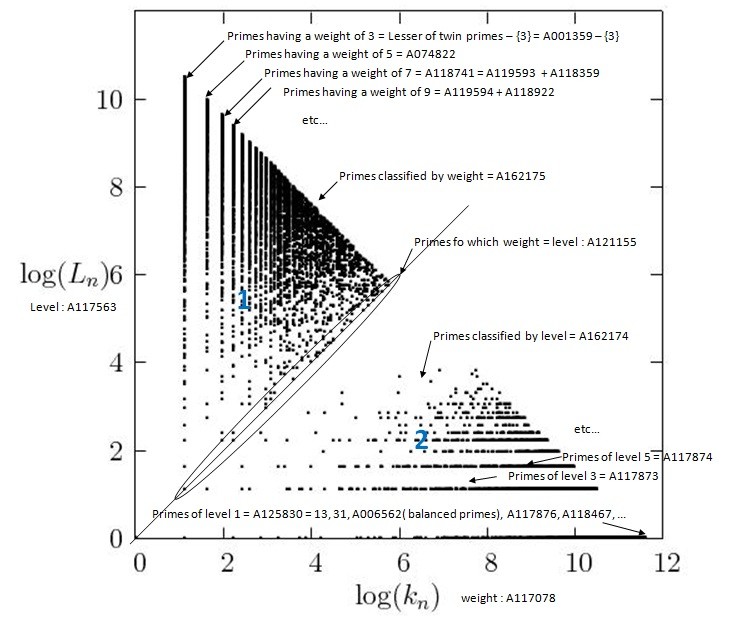
 It's a decomposition of positive integers. The weight is the smallest such that in the Euclidean division of a number by its weight, the remainder is the jump (first difference, gap). The quotient will be the level. So to decompose a(n), we need a(n+1) with a(n+1)>a(n) (strictly increasing sequence), the decomposition is possible if a(n+1)<3/2×a(n) and we have the unique decomposition a(n) = weight × level + jump.
It's a decomposition of positive integers. The weight is the smallest such that in the Euclidean division of a number by its weight, the remainder is the jump (first difference, gap). The quotient will be the level. So to decompose a(n), we need a(n+1) with a(n+1)>a(n) (strictly increasing sequence), the decomposition is possible if a(n+1)<3/2×a(n) and we have the unique decomposition a(n) = weight × level + jump.